1171 views
1171 views

BERLIN - In October 2022, I published an article on large language model (LLM) selection for specific natural language processing (NLP) use cases, such as conversation, translation, and summarization. Since then, artificial intelligence (AI) has made a huge step forward, and this article will review some of the trends that have emerged during the past months, as well as their implications for AI builders. Specifically, it will cover the topics of task selection for autoregressive models and the evolving trade-offs between commercial and open-source LLMs, as well as LLM integration and the mitigation of failures in production.
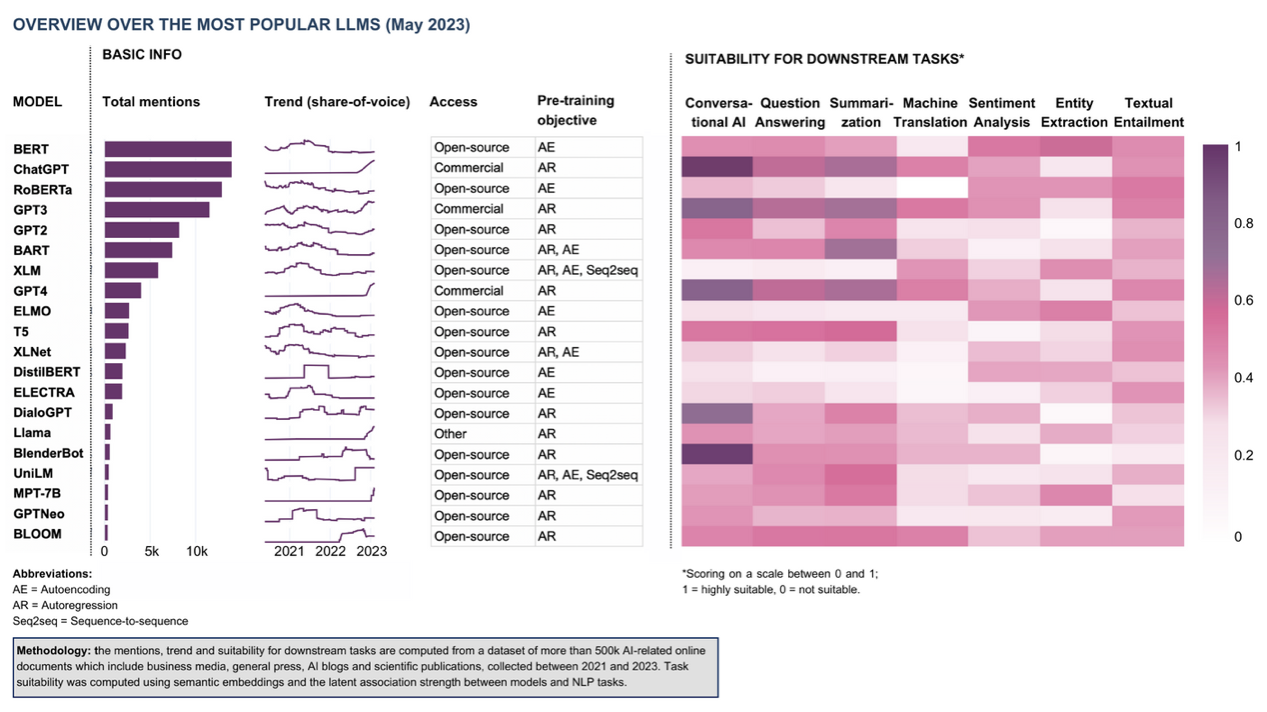
Table 1: Selection of popular LLMs (by number of mentions) as of May 2023. The mentions, trends, and suitability for downstream tasks are computed from a dataset of more than 500,000 AI-related online documents, including business media, the general press, AI blogs, and scientific publications. Task suitability was computed using semantic embeddings and the latent association strength between models and NLP tasks.
1. Generative AI pushes autoregressive models, while autoencoding models await their moment
For many AI companies, it seems like ChatGPT has become the ultimate competitor. When pitching my analytics startups in earlier days, people would frequently challenge me with questions like “What will you do if Google (Facebook, Alibaba, Yandex…) comes around the corner and does the same?” Now, the question du jour is more like “Why can’t you use ChatGPT to do this?”
The short answer is that ChatGPT is great for many things, but it does not even come close to cove
The content herein is subject to copyright by The Yuan. All rights reserved. The content of the services is owned or licensed to The Yuan. Such content from The Yuan may be shared and reprinted but must clearly identify The Yuan as its original source. Content from a third-party copyright holder identified in the copyright notice contained in such third party’s content appearing in The Yuan must likewise be clearly labeled as such. Continue with Linkedin
Continue with Linkedin
 Continue with Google
Continue with Google