







 1060 views
1060 views
SAN FRANCISCO - Large language models (LLMs) refer to a type of AI algorithm that uses deep learning (DL) techniques and large datasets - usually petabytes in size - to understand, summarize, generate, and predict new content. LLMs are becoming increasingly popular thanks to their wide range of uses, among them as conversational chatbots and in translation, text generation, and content summary.1
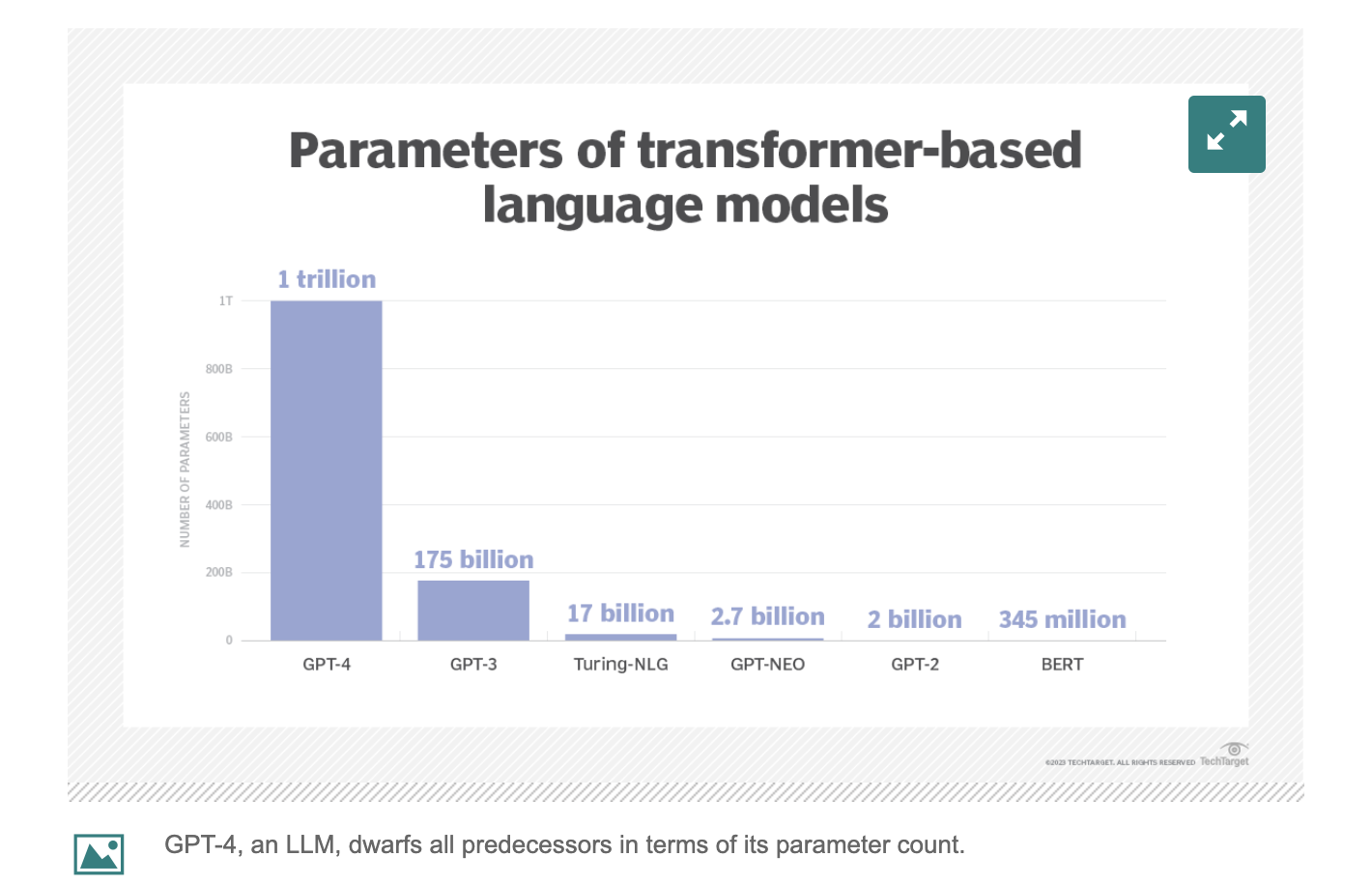
As the following diagram shows, LLMs have significantly more parameters embedded into their models than conventional ones - which increases the size of an LLM’s memory, as well as its performance.
Self-instruction bolsters LLMs
Much recent research focuses on building models that follow natural language instructions, e.g., figuring out the zip code for an address. These developments are powered by two key components: large pre-trained language models and human-written instructions. Collecting such instruction data is costly and often does not yield enough diversity as a result, especially as compared to the increasing demand for this developing technology. Self-instructing was thus devised as a solution to this issue by automating the instruction-data creation process.2
Workings of self-instruction
Self-instructing typically begins by compiling a small number - e.g., 175, as demonstrated below - of manually written instructions. The model is prompted to generate more instructions for new tasks by using the 175 original instructions given, and also creates potential inputs and outputs for the newly generated tasks. Various heuristics automatically filter out low-quality, repeated instructions, and add valid o
The content herein is subject to copyright by The Yuan. All rights reserved. The content of the services is owned or licensed to The Yuan. Such content from The Yuan may be shared and reprinted but must clearly identify The Yuan as its original source. Content from a third-party copyright holder identified in the copyright notice contained in such third party’s content appearing in The Yuan must likewise be clearly labeled as such. Continue with Linkedin
Continue with Linkedin
 Continue with Google
Continue with Google










