1494 views
1494 views

PHILADELPHIA - Federated learning (FL) is a machine learning (ML) technique that trains an algorithm, without any exchanging, across multiple decentralized edge devices or servers that hold local data samples. This approach differs from traditional centralized ML techniques in which all local datasets are uploaded to a single server, as well as from more traditional decentralized approaches which assume that local data samples are identically distributed.
Personal data is sent to a central server where it is analyzed under the more traditional system, and relevant information is used to alter the algorithm. FL offers enhanced user privacy, since most personal data remains on the device of a single person. Algorithms train directly on user devices and send back only relevant data summaries, not the data as a whole. This allows companies to improve their algorithms without needing to collect all the data from a user.
Fl allows multiple actors to build a common, robust ML model without sharing data, thus addressing critical issues such as data privacy, data security, data access rights and access to heterogeneous data. Its applications span a wide range of industries, including defense, telecommunications, Internet of Things (IoT), and pharmaceuticals.
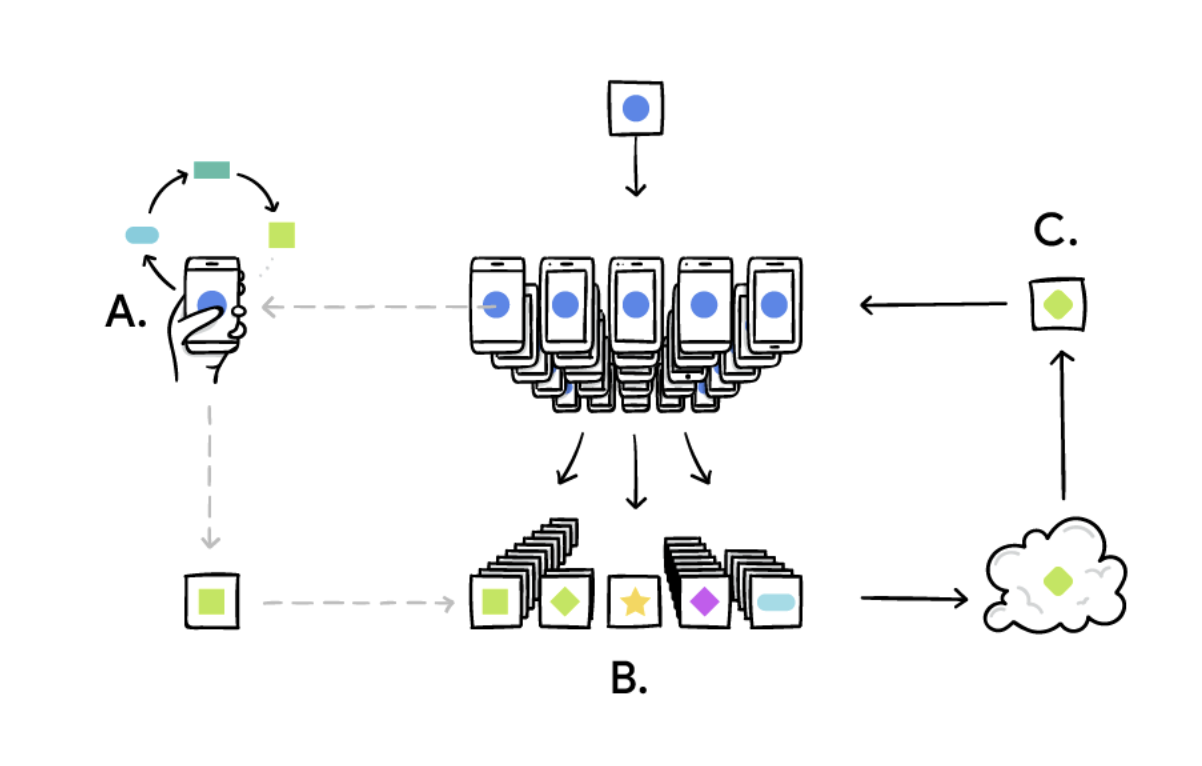 The main difference between FL and distributed learning (DL) lies in the assumptions made about the properties of the local datasets, since the original aim of DL is to paralyze computing power, whereas FL’s is to train on heterogeneous datasets. Although DL is also intended to train a single model on multiple servers, a common underlying assumption is that the local datasets are distributed identically and are roughly the same size.
The main difference between FL and distributed learning (DL) lies in the assumptions made about the properties of the local datasets, since the original aim of DL is to paralyze computing power, whereas FL’s is to train on heterogeneous datasets. Although DL is also intended to train a single model on multiple servers, a common underlying assumption is that the local datasets are distributed identically and are roughly the same size.
None of these hypotheses are made for FL. Instead, datasets are typically heterogeneous, and their sizes can s
The content herein is subject to copyright by The Yuan. All rights reserved. The content of the services is owned or licensed to The Yuan. Such content from The Yuan may be shared and reprinted but must clearly identify The Yuan as its original source. Content from a third-party copyright holder identified in the copyright notice contained in such third party’s content appearing in The Yuan must likewise be clearly labeled as such. Continue with Linkedin
Continue with Linkedin
 Continue with Google
Continue with Google