







 1276 views
1276 views
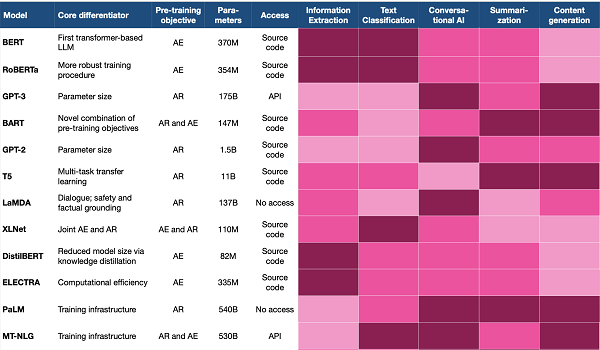
BERLIN - With their impressive ability to produce text, Large Language Models (LLMs) have become the backbone of modern Natural Language Processing (NLP).
They are traditionally pre-trained by academic institutions and big tech companies such as OpenAI, Microsoft and NVIDIA, and then most of them are made available for public use. This plug-and-play approach is also an important step towards large-scale adoption of artificial intelligence (AI) - instead of spending huge resources on the training of models with general linguistic knowledge, businesses can now focus on fine-tuning existing LLMs for specific use cases.
However, picking the right model can be tricky in the business scenario. Users and other stakeholders must make their way through a frequently changing landscape of language models and related innovations. Improvements address different components of the language model, including its training data, pre-training objective, architecture, and fine-tuning approach - one could write entire books on each of these aspects. On top of all the research, all the marketing buzz and the intriguing aura of Artificial General Intelligence around huge language models obfuscate things even more.
This article explains the main concepts of and differences between various LLMs and seeks to provide business stakeholders with a language for efficient interaction with developers and other research and development players. For broader coverage, the article includes analyses that are rooted in many NLP-related publications. Although the mathematical details of language models will not be covered in detail here, these can be easily retrieved by referring to the references.
The article is structured as follows: first, various language models will be situated in the context of the evolving NLP landscape. The second section will explain how LLMs are built and pre-trained, and the last part of the article describes the f
The content herein is subject to copyright by The Yuan. All rights reserved. The content of the services is owned or licensed to The Yuan. Such content from The Yuan may be shared and reprinted but must clearly identify The Yuan as its original source. Content from a third-party copyright holder identified in the copyright notice contained in such third party’s content appearing in The Yuan must likewise be clearly labeled as such. Continue with Linkedin
Continue with Linkedin
 Continue with Google
Continue with Google










